F# + Scriban - HTML Template Parsing Benchmarks
Essay - Published: 2023.11.22 | 5 min read (1,320 words)
benchmark | create | fsharp | html | scriban | tech
DISCLOSURE: If you buy through affiliate links, I may earn a small commission. (disclosures)
I've been experimenting with server-side rendering HTML templates in F# / dotnet as a potential evolution for faster, simpler UIs in CloudSeed - my F# Web API boilerplate. Scriban was a top contender for templating my HTML strings as it's popular in the C# / dotnet community and has a clean, performant API.
As I built UIs with Scriban I noticed that there was an opportunity to cache some templates. But I wasn't sure how impactful this would be and thus whether it would be worth doing.
In this post, we'll explore:
Q: What's the performance difference between Re-Parsing a Template on every call and utilizing a cached Template in Scriban?
Answer
Overall Cached Templates are faster than re-Parsing Templates every time by 5-30%. The difference is more pronounced for smaller templates and becomes less meaningful for larger Templates as Rendering takes up more work. That said, the absolute time differences are incredibly small (< 1 ms) so both approaches will likely scale well (and often much better than other popular approaches like insert-favorite-js-framework-here)
- 10 Items -> Cached faster (30%, 0.05ms)
- 100 Items -> Cached faster (20%, 0.1ms)
- 500 Items -> Raw faster (7%, 0.2ms)
- 800 Items -> Cached faster (4%, 0.2ms)
- 1000 Items -> FAIL (Reflection limit)
In the rest of this post we'll explore these benchmark results in greater detail:
- Benchmark Setup
- Detailed Results
- Full Benchmark Code
Source Code:
- Benchmark Replit
- Full Source Code: Available at bottom of post
Benchmark Setup
I wanted to approximate a "real-world" example for utilizing the Scriban library for HTML templating. To that end, I built a simple HTML template that would display data in a table. Each row is a string which we pre-compute before the benchmarks.
Simple Template
// HAMY: A simple html doc
let testTemplate1 =
"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sentinels Example</title>
</head>
<body>
<main>
<h1>Sentinels Table</h1>
</main>
<table>
<tr>
<th>item</th>
</tr>
{{ for item in Items }}
<tr>
<td>{{ item }}</td>
</tr>
{{ end }}
</table>
</body>
</html>
"""
This allows us to test the full life cycle of a template which is closer to what I cared about for my usage:
- Parsing
- Rendering - with data population
For this benchmark I wanted to test two versions:
- CachedParser - We Parse the template then benchmark rendering with the
CachedParser - RawParser - We Parse and Render the template every time we call it.
let cachedParser
(template : string)
=
let compiledTemplate = Scriban.Template.Parse(template)
fun (props : TemplateProps) ->
compiledTemplate.Render(
props,
memberRenamer = fun m -> m.Name)
let rawParser
(template : string)
(props : TemplateProps)
=
let compiledTemplate = Scriban.Template.Parse(template)
compiledTemplate.Render(
props,
memberRenamer = fun m -> m.Name)
let cachedParserTest1 = cachedParser testTemplate1
let rawParserTest1 = rawParser testTemplate1
For Benchmarking, I utilized BenchmarkDotNet - a popular, battle-hardened framework for running benchmarks w dotnet.
Detailed Results
I ran the Benchmark multiple times with varying data sizes to get a better idea of how the library performed under different circumstances (larger and smaller HTML templates).
Terms:
- ms = millisecond (0.001 seconds)
- us = microsecond (0.000001 seconds)
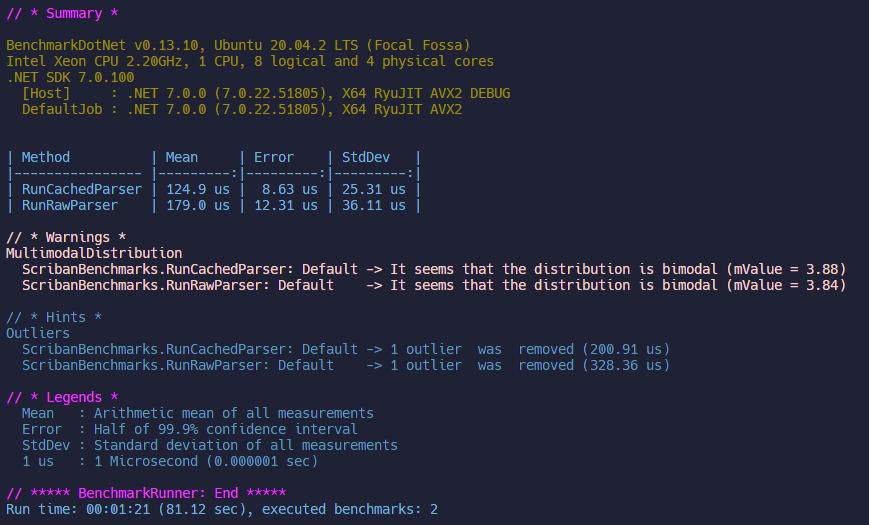
10 Items
Overall: Cached faster (30%, 0.05ms)
CachedParser:
- Mean: 0.125 ms
- Error: 0.009 ms
- StdDev: 0.025 ms
RawParser:
- Mean: 0.179 ms
- Error: 0.012 ms
- StdDev: 0.036 ms
CachedParser is significantly faster but the absolute difference is about 0.05ms which is essentially unnoticeable. For small templates, Scriban is quite fast.
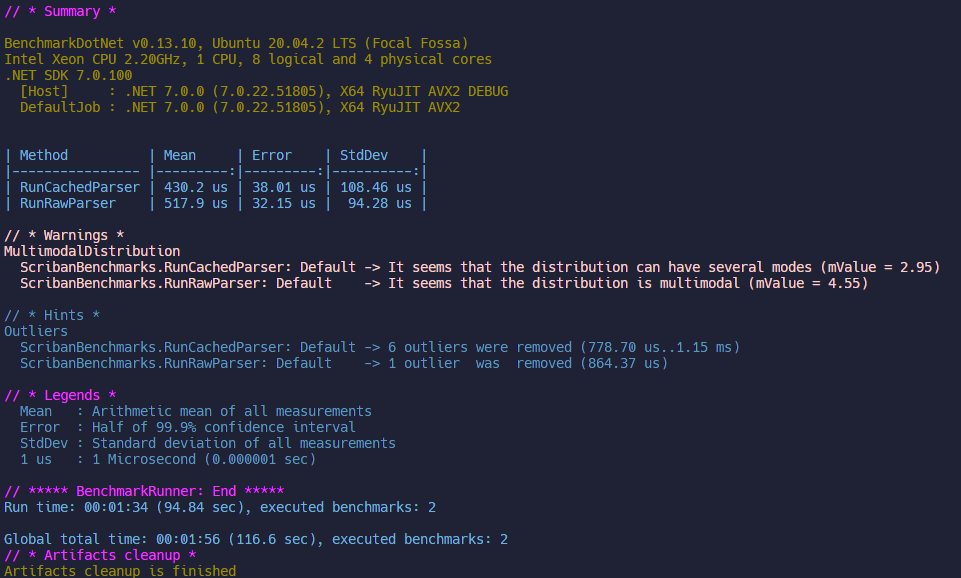
100 Items
Overall: Cached faster (20%, 0.1ms)
CachedParser:
- Mean: 0.430 ms
- Error: 0.038 ms
- StdDev: 0.108 ms
RawParser:
- Mean: 0.518 ms
- Error: 0.032 ms
- StdDev: 0.094 ms
Here Cached still has an edge of ab 20% but at 0.1ms it's still essentially unnoticeable. Interestingly it seems that the work is scaling sublinearly - we required 10 times more data population but only needed ~4x more time to do so.
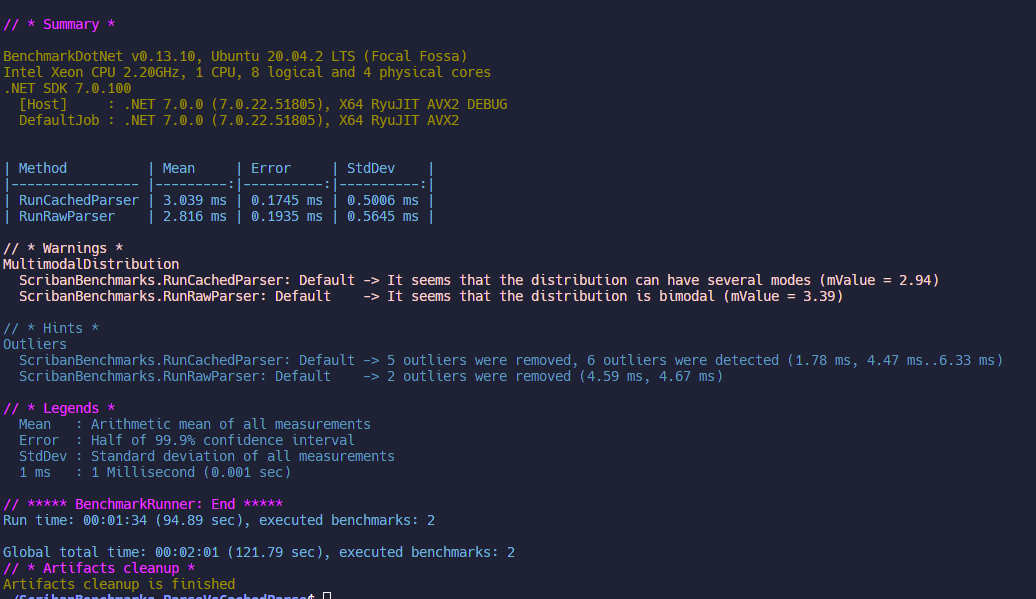
500 Items
Overall: Raw faster (7%, 0.2ms)
CachedParser:
- Mean: 3.039 ms
- Error: 0.175 ms
- StdDev: 0.501 ms
RawParser:
- Mean: 2.816 ms
- Error: 0.194 ms
- StdDev: 0.565 ms
Here we start to push Scriban a bit. It's unlikely that you'll want to actually render 500 items in a list like this but I think this starts to show us what it's like if we have a more complex template populating lots of different data totaling a few hundred fields. Still Scriban handles it quite well with a mean of 3 ms (unnoticeable to a human though perhaps noticeable to our systems) and with the raw / cached parsers just 0.2 ms different.
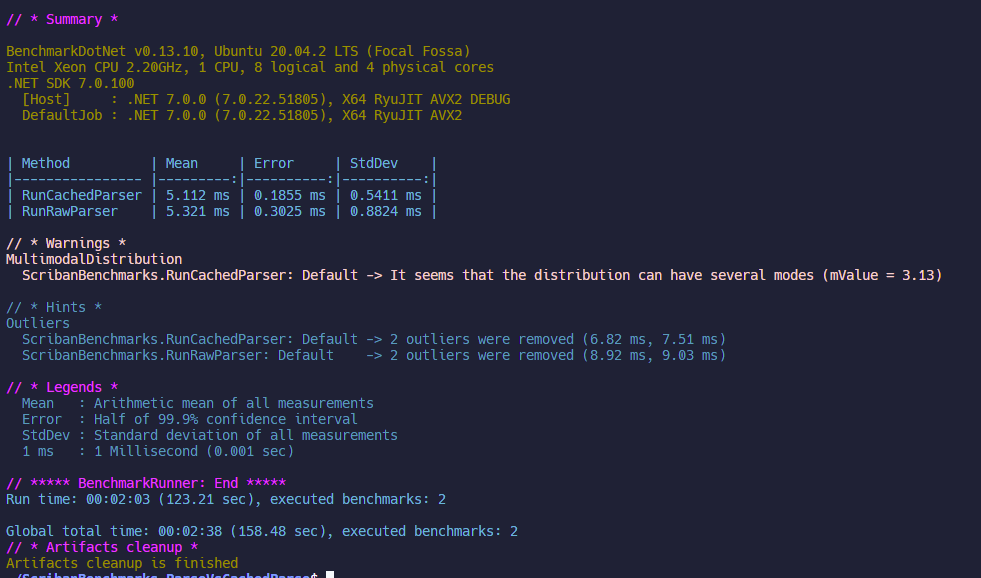
800 Items
Overall: Cached faster (4%, 0.2ms)
CachedParser:
- Mean: 5.112 ms
- Error: 0.186 ms
- StdDev: 0.541 ms
RawParser:
- Mean: 5.321 ms
- Error: 0.303 ms
- StdDev: 0.882 ms
Here we reach the extremes of what Scriban is built for (seriously, at 1000 items we broke it). Yet it still performs remarkably well with ~5 ms renders for a truly unreasonable amount of data being displayed on screen. Even at this juncture, the difference between raw and cached parsing remains small (~0.2 ms) giving me confidence that both are generally fine approaches with little / no performance difference between them.
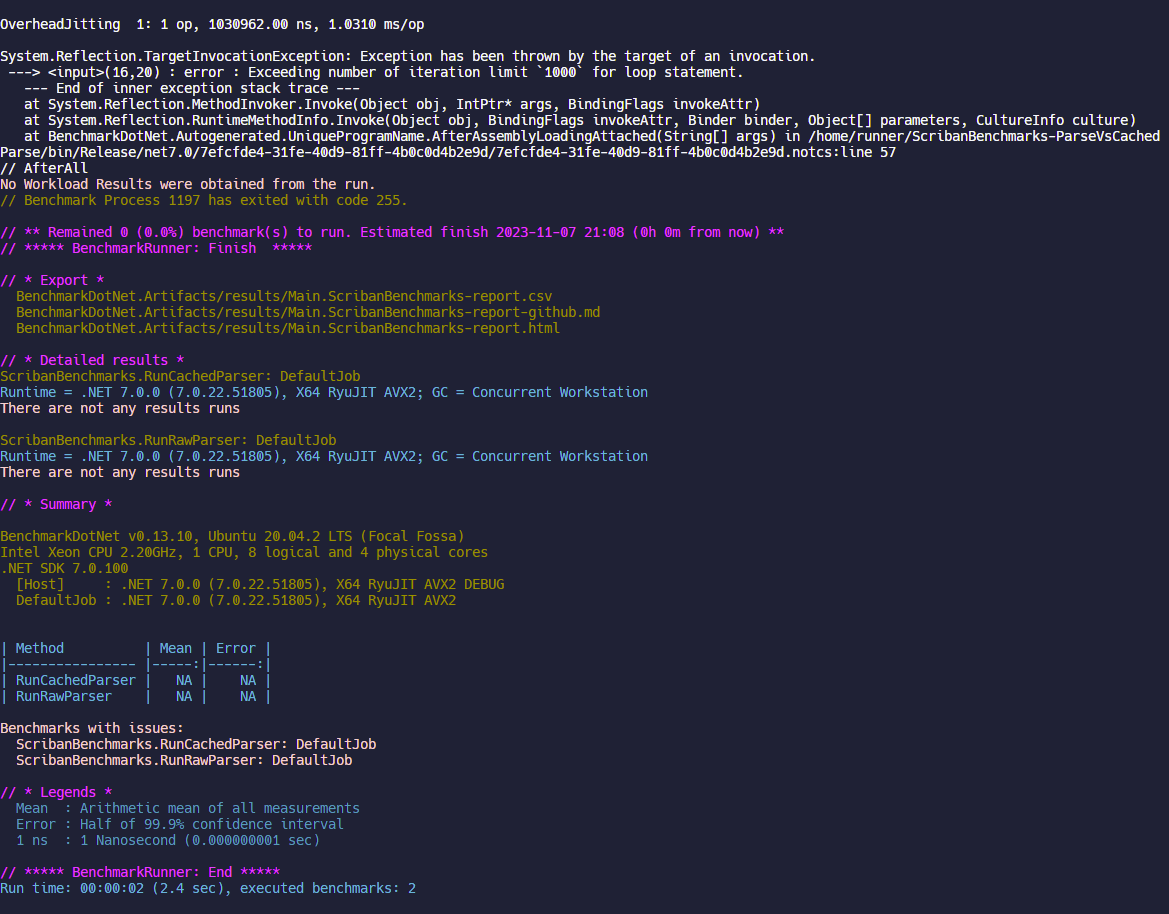
1000 Items
Overall: Failed
Here we seem to push Scriban to its limits. It seems we get blocked by a System.Reflection.TargetInvocationException presumably for doing too many iterations as part of this process. My guess is this limit is here because Reflection is generally slow / expensive and it wants to prevent you from crashing yourself accidentally. My other guess is that we could probably lift this limit with some configuration but I think 1000 items is mostly unnecessary for UI renders and thus it's okay this breaks for our purposes.
Full Benchmark Code
Here's a dump of the benchmark code as used to get these results. You can also run this benchmark on Replit.
open BenchmarkDotNet.Attributes
open BenchmarkDotNet.Running
open Scriban
open System
(*
* ToRun: dotnet run -c Release
*)
type TemplateProps =
{
Items : string list
}
type ScribanBenchmarks() =
let itemCount = 800
let testItems =
seq {0 .. itemCount}
|> Seq.map
(fun _ -> Guid.NewGuid().ToString())
|> Seq.toList
// HAMY: A simple html doc
let testTemplate1 =
"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sentinels Example</title>
</head>
<body>
<main>
<h1>Sentinels Table</h1>
</main>
<table>
<tr>
<th>item</th>
</tr>
{{ for item in Items }}
<tr>
<td>{{ item }}</td>
</tr>
{{ end }}
</table>
</body>
</html>
"""
let cachedParser
(template : string)
=
let compiledTemplate = Scriban.Template.Parse(template)
fun (props : TemplateProps) ->
compiledTemplate.Render(
props,
// HAMY: Overload memberRenamer so var names are the same
// Source: https://github.com/scriban/scriban/blob/master/doc/runtime.md#member-renamer
memberRenamer = fun m -> m.Name)
let rawParser
(template : string)
(props : TemplateProps)
=
let compiledTemplate = Scriban.Template.Parse(template)
compiledTemplate.Render(
props,
// HAMY: Overload memberRenamer so var names are the same
// Source: https://github.com/scriban/scriban/blob/master/doc/runtime.md#member-renamer
memberRenamer = fun m -> m.Name)
let cachedParserTest1 = cachedParser testTemplate1
let rawParserTest1 = rawParser testTemplate1
[<Benchmark>]
member __.RunCachedParser() =
cachedParserTest1 { Items = testItems }
[<Benchmark>]
member __.RunRawParser() =
rawParserTest1 { Items = testItems }
[<EntryPoint>]
let main argv =
printfn "Hello World from F#!"
let summary = BenchmarkRunner.Run<ScribanBenchmarks>();
0 // return an integer exit code
Next
I'm pleasantly surprised with how easy / performant HTML template parsing has been in F# / dotnet. I'll likely continue experimenting and try using it for more of my projects.
If you liked this post, you might also like:
Want more like this?
The best way to support my work is to like / comment / share this post on your favorite socials.