Types vs No Types - How Types Allow Code to Scale across Developers, Organizations, and Lines of Code
Essay - Published: 2024.09.04 | 7 min read (1,767 words)
create | featured | programming | tech | types
DISCLOSURE: If you buy through affiliate links, I may earn a small commission. (disclosures)
Static vs dynamic types is one of the many evergreen arguments in the software engineering community. I'm not going to argue static vs dynamic - they both have their pros / cons and largely this is a false dichotomoy, there's a whole matrix of strict -> loose, static -> inferred typing paradigms these don't represent.
What I am going to do is illustrate the difference between typed and non-typed logic flows to highlight how these approaches scale across usecases, organizations, and codebases.
What are Types?
Essentially types are labels on code flows. They say what kind of values pass through this code flow. This is useful because if you know what kind of value is in a flow, you can have a better idea of what it represents and how you might (and might not) want to use it.
I often like to think of code flows like wires and types as adding color codes to the wire. It doesn't change the wire itself, it just makes it easier to spot what is in the wire and thus intuit what its purpose / usefulness is.
For a deeper dive into logic flows as wires, see: Why Type-safe Programming Languages are better than Dynamic and Lead to Faster, Safer Software at Scale.
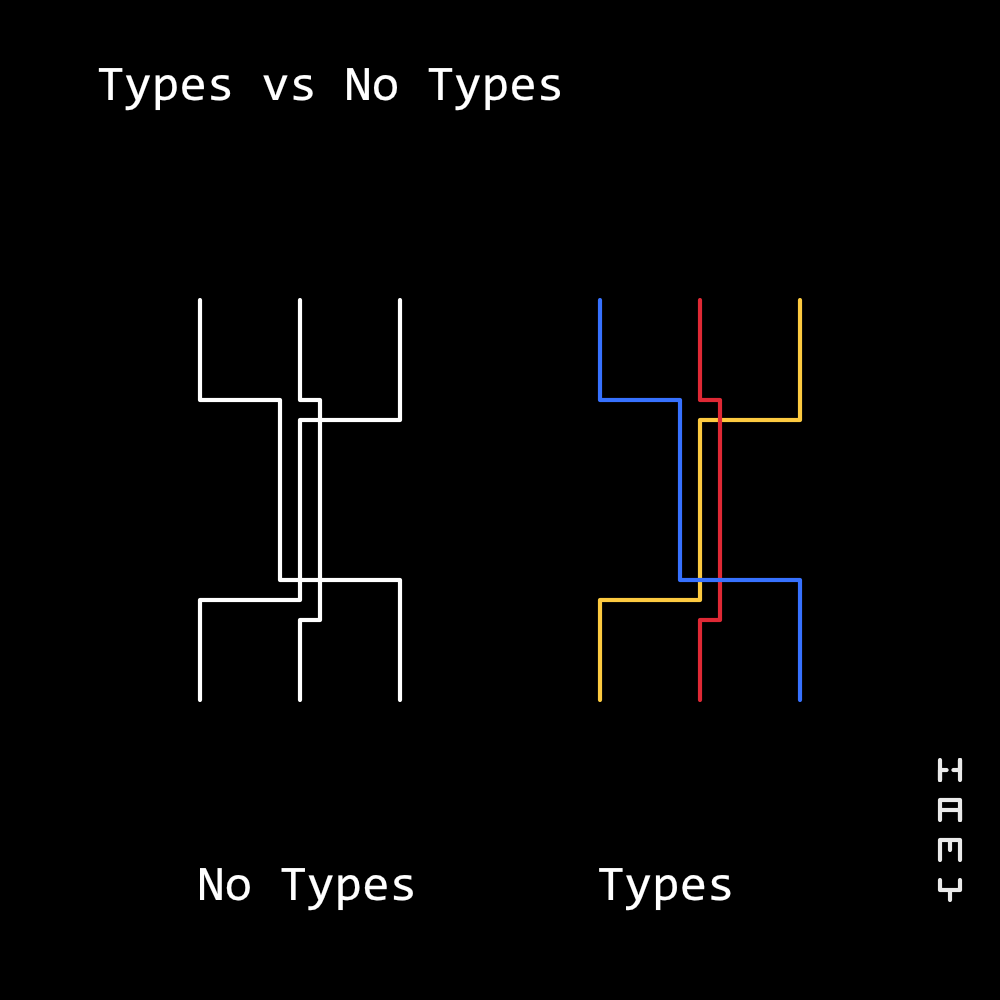
Why are Types Useful?
Types are useful for code flows for the same reason labels are useful on wires - they help you figure out what a wire does and intuit what it's used for, necessary context if you're going to change the wiring.
With just a few things to wire (like your personal desk) it doesn't really matter if you have a good labeling / wire management system - you can probably figure it out. But once you get up to 100s of wires (like a data center rack) it starts to become a burden to figure out what each wire does just to rewire something.
The truth is software engineering is all about wiring and rewiring code flows so this idea of making wiring / rewiring easier is directly applicable to building software faster and safer.
Now there are many ways to manage wires, here are a few common ones:
- No labels, no management (dynamic types, poor code structure) - Just plug stuff in and leave the wires hanging. This works for small systems (a personal desk) but is a bit of a pain to rewire. You have to trace wiring by looking at the ends, pulling on stuff, then unwinding it from the mess of cables. (this is probably what the back of your parent's entertainment system looks like)
- No labels, some management (dynamic types, decent code structure) - Just plug stuff in and maybe wrap the cords up. Still need to trace the wires and pull on stuff but unwinding it is usually a bit easier cause not in a bunch of knots. (this is probably what your personal workspace desk wiring looks like)
- One Sticky Note label on the ends (dynamic types with value asserts) - Makes it easier to see what a label is for so can quickly change it out at each end. Still need to trace it in the middle though cause unclear what each cord is. (this is probbly what your house's fuse box looks like)
- Sticky Note labels at regular intervals (dynamic types with value asserts and good naming) - Same as above but now easier to see what a cord is in the middle. (this is probably what your building's plumbing pipes look like)
- Color-coded wires so each wire is unique by look (types) - Same as above but now we don't need to manage the labels, it's baked into the wire. (this is probably what your datacenter's cabling looks like)
All of these management techniques aim to accomplish the same thing - Make it easier to manage / change our system by adding visibility into what each wire is / does so we can avoid breaking it.
Types vs No Types for Software at Scale
Now let's think about how our labeling systems work for wiring at scale. If we think about what large engineering teams do, it's basically just a bunch of code flow plumbing on a large codebase - this means tons of different wires going every which away, 100s of changes going out every day, and very unlikely any one engineer understands the full wiring layout.
What this means is that we've got a wire management problem at scale:
- Bunch of maintainers
- No one knows what all the wires do
- 100s of changes to the wiring every day
Now let's see how our wire management solutions stack up to this:
First, some strategies we generally want to avoid:
- No labels, no management (dynamic types, poor code structure) - This is just bad code, don't do this. It may work for your desk but certainly not what you want to bank your company on.
- No labels, some management (dynamic types, decent code structure) - This is okay for small teams and codebases. However as soon as you get a new dev on the team it's going to be apparent how non-obvious these wires are from the frequency of mistakes leading to breakages.
Now some strategies for wire management that are more common practice in the industry:
One Sticky Note label on the ends (dynamic types with value asserts)
This can work for a while. You basically have asserts at the end of the flows which gives you confidence that at least the stuff in the middle isn't breaking everything.
However this means that during development devs will often end up breaking stuff in the middle on accident and won't know about it until test time. Then it'll take a long time to fix - they must trace the wire all the way up to where the values come from and all the way down to where they're going to figure out what's broken. This tracing can be tedious and time consuming depending on how convoluted the wire is.
Moreover it's possible that the wire will change out from under you as you're working. So even if you do a full trace yourself during the project, it may no longer be accurate by the time you're ready to commit your changes requiring you to do a full trace once again because there's no other way to get this info.
Sticky Note labels at regular intervals (dynamic types with value asserts and good naming)
This one is pretty good because you can often save on tracing time - just check the nearest label and you have a good idea of what's in the wire.
Unfortunately a good idea is not the same as knowing for sure. Even though this variable has a nice name and our system isn't broken (the value asserts on each end are good) there's very little enforcing that this intermediate type is what it says it is. This is a common source of bugs - you think it's a string but actually it's a null. It's also a common source of confusion - variable names just like source code comments can easily become stale leading to future devs thinking it's load-bearing when perhaps it's been out of date for several months.
This will essentially let you know when you've broken the system but not where in the system it's broken. Again - incurring a full trace cost to figure out where in the flow the values forked from what the naming was.
Now a fix to this of course is to not just use good naming at regular intervals but also to use value asserts at regular intervals. This is a reasonable solution and while it incurs extra runtime cost, I think is usually worthwhile - this is often the closest you can get to type safety in dynamic languages.
The problem with this in turn though is that you only find out if you did the wiring incorrectly once you try the wire itself. This is like electrical wiring IRL - we can wire what looks correct but we need to flip the switch to see if the light actually comes on.
It works - this is a viable solution. But we do incur the cost of not knowing if wiring works until we explicitly test it. Generally this means longer cycle times and a bit more rework as we go back and forth from change -> test. It also means that if you are not testing 100% of your wires (i.e. code flows), it's very easy for a bad wire connection to go unnoticed until you need it and find out the thing is broken.
Color-coded wires so each wire is unique by look (types)
This one's interesting because it combines a lot of the benefits of the ones above it.
- Fast lookups for what's in the wire (labels)
- Easy to spot inconsistencies in connections (value asserts)
- Automatic error checking - you can't just plug a yellow wire into a blue wire, you need a convertor! (types)
It accomplishes what all the above approaches attempt but with less work.
It doesn't remove the need to test or to structure your code well - you still should flip the switch and make sure the light comes on and not tie all your wires in knots. But it does make it a bit easier to manage because it removes several classes of common errors.
Next
I'm not saying that you can't write good software without types. I am saying that types are a simple tool for avoiding common pitfalls in software engineering (wiring things incorrectly) and fixing them faster (blue wire to blue wire, yellow wire to yellow wire).
There are other ways to accomplish the same things but types are the best Simple Scalable System I've found to do so.
For a more in-depth exploration of types vs no types and the code flows as wires metaphor, checkout my full essay: Why Type-safe Programming Languages are better than Dynamic and Lead to Faster, Safer Software at Scale
If you liked this post you might also like:
Want more like this?
The best way to support my work is to like / comment / share this post on your favorite socials.
Inbound Links
- Why High-Level Rust Wins Over Other High-Level Languages for Agentic Engineering
- Why Rust Wins in the Age of AI
- The Missing Programming Language - Why There's No S-Tier Language (Yet)
- 5 AI Coding Best Practices from a Google AI Director (That Actually Work)
- 5 Reasons to Stop Throwing Exceptions - and What To Do Instead for a more Robust, Composable, and Performant Codebase
- What are Branded Types? (And When You Should Use Them) in TypeScript
- TypeScript - Errors as Values vs Exceptions Performance Benchmarks
- HAMY LABS - 2024 Review
- Type-Safe Currency Conversion with F# Units of Measure
- Why you should use Pydantic Dataclasses instead of Python Dataclasses
Outbound Links
- Why Type-safe Programming Languages are better than Dynamic and Lead to Faster, Safer Software at Scale
- Simple Scalable Systems - How to find 80/20 Silver Bullet Solutions for any domain
- How to Write Simple Tests that Scale with Codebases, Organizations, and Changing Requirements
- 3 Areas I'm exploring to build more side projects faster and cheaper in 2024
- 5 Reasons F# is a great Python alternative for scripting, side projects, and enterprise applications